对服务器状态的监控能够有效防止因资源不足等原因导致的应用服务异常,因此安装监控是很有必要的
一、安装Prometheus服务端
1.安装go环境
先关闭防火墙(也可以只放开必要端口)
上传go的tar包
tar xf go1.13.1.linux-amd64.tar.gz
mv go /usr/local/
vi /etc/profile
在最后一行添加
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
source /etc/profile
执行go version有版本号即安装成功
2.安装Prometheus
上传Prometheus的tar包
tar xf prometheus-2.53.3.linux-amd64.tar.gz
mv prometheus-2.53.3.linux-amd64 /usr/local
mv prometheus-2.53.3.linux-amd64 prometheus
cd /usr/local/prometheus
./prometheus --config.file=/usr/local/prometheus/prometheus.yml &
打开http://Prometheus服务端IP地址:9090 查看是否有页面,有页面说明安装成功了,Ctrl+C 结束掉Prometheus进程
3.配置Prometheus的system服务
vi /etc/systemd/system/prometheus.service
写入以下内容
[Unit]
Description=Prometheus Monitoring System
Documentation=Prometheus Monitoring System
[Service]
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--web.listen-address=:9090
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动Prometheus的system服务服务,设置开机自启,并检查服务开启状态
systemctl daemon-reload
systemctl enable prometheus
systemctl start prometheus
systemctl status prometheus
二、安装Grafana
1.上传Grafana包并本地安装
yum localinstall grafana-enterprise-11.4.0-1.x86_64.rpm
2.设置开机自启
systemctl daemon-reload
systemctl enable grafana-server.service
systemctl start grafana-server.service
3.访问Grafana
浏览器访问http:/服务端IP地址:3000,即可打开grafana页面,默认用户名密码都是admin,初次登录会要求修改默认的登录密码
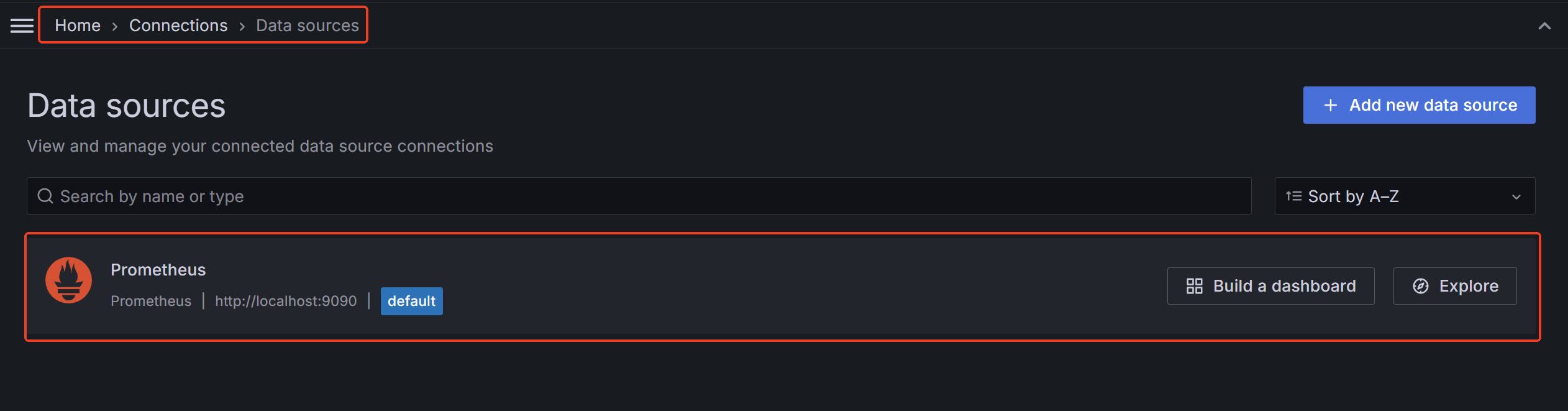
4.添加Prometheus数据源
三、安装 node-exporter(只在被监控机器安装)
先关闭防火墙(也可以只放开必要端口)
1.上传node-exporter的tar包后解压
tar xf node_exporter-1.8.1.linux-amd64.tar.gz -C /usr/local
mv /usr/local/node_exporter-0.18.1.linux-amd64 /usr/local/node_exporter
2.启动node-exporter
cd /usr/local/node_exporter
./node_exporter
访问http://被监控机器IP地址:9100/metrics 出现下图内容即表示服务开启成功

3.配置node-exporter的system服务
Ctrl+C 结束掉node_exporter进程,创建node_exporter服务,让node_exporter以服务的方式,开机自启。
vi /etc/systemd/system/node_exporter.service
写入以下内容
[Unit]
Description=node_exporter
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable node_exporter
systemctl start node_exporter
systemctl status node_exporter
四、添加需要监控的机器(只在Prometheus服务端机器上配置)
1.修改Prometheus配置
cd /usr/local/prometheus
vi prometheus.yml
添加/修改以下内容,增添被监控机器
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "linux"
static_configs:
- targets: ["Prometheus服务端机器IP地址:9090"]
- targets: ["被监控机器IP地址:9100"]
- targets: ["被监控机器IP地址:9100"]
- job_name: "windows"
static_configs:
- targets: ["被监控机器IP地址:9182"]
- targets: ["被监控机器IP地址:9182"]
保存退出,并重启Prometheus服务
systemctl restart prometheus
2.访问 http://Prometheus服务端IP地址:9090/targets

被监控机器加入成功
3.配置Grafana的dashboard
这里我们选用8919模板,十分的好看
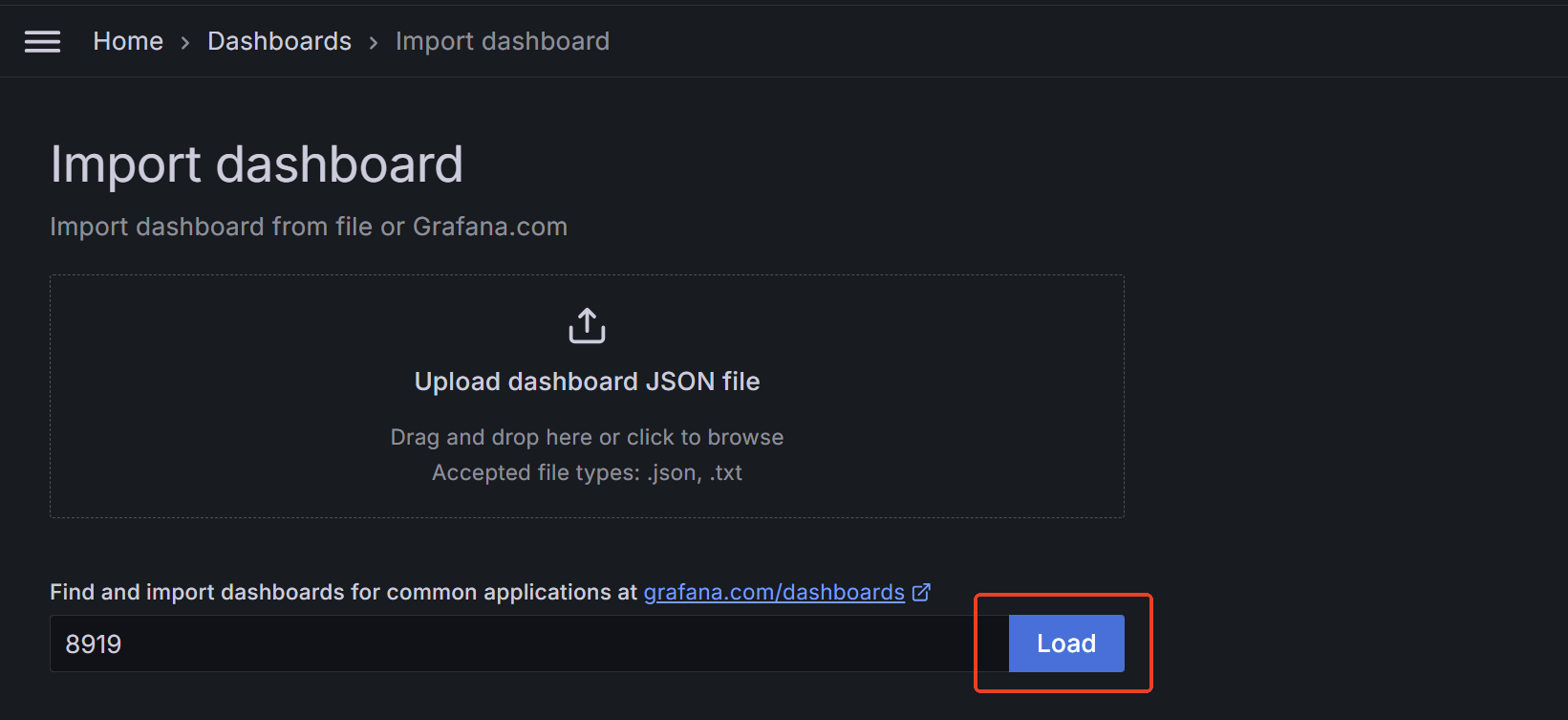
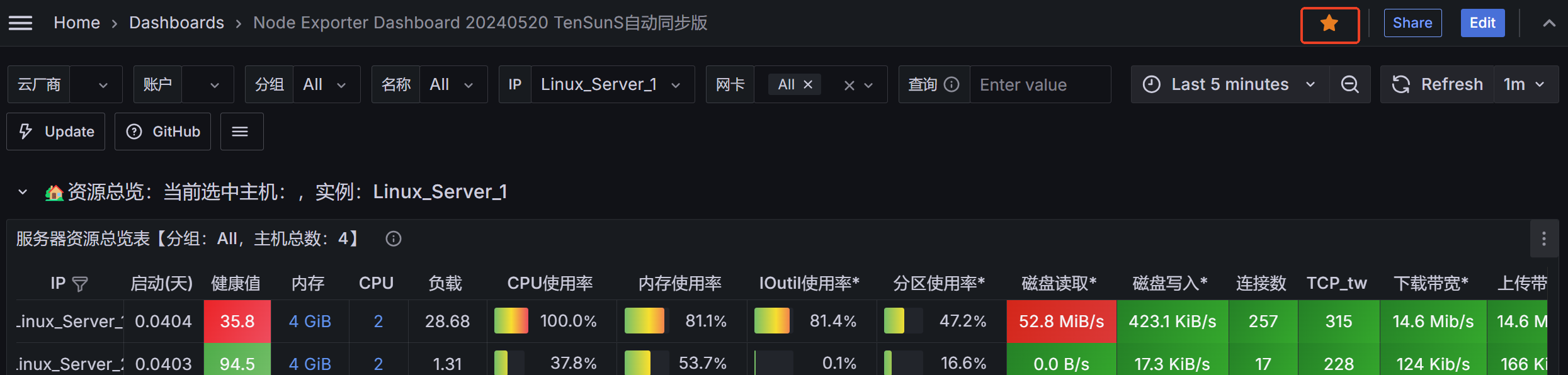
出现此界面Prometheus服务端+Grafana+被监控机器添加设置完成
ps.如果浏览器访问Grafana监控面板出现没有数据的情况,可能和你的电脑时间与Linux服务端时间不一致有关
五、钉钉报警
1.安装Alertmanager
tar -xf alertmanager-0.25.0-rc.2.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/alertmanager-0.25.0-rc.2.linux-amd64.tar.gz /usr/local/alertmanager
2.配置Alertmanager的system服务
vi /lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager for Prometheus
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data/
Restart=on-failur
ExecStop=/bin/kill -9 $MAINPID
[Install]
WantedBy=multi-user.target
3.配置报警规则
mkdir -p /usr/local/prometheus/rules/linux
mkdir -p /usr/local/prometheus/rules/windows
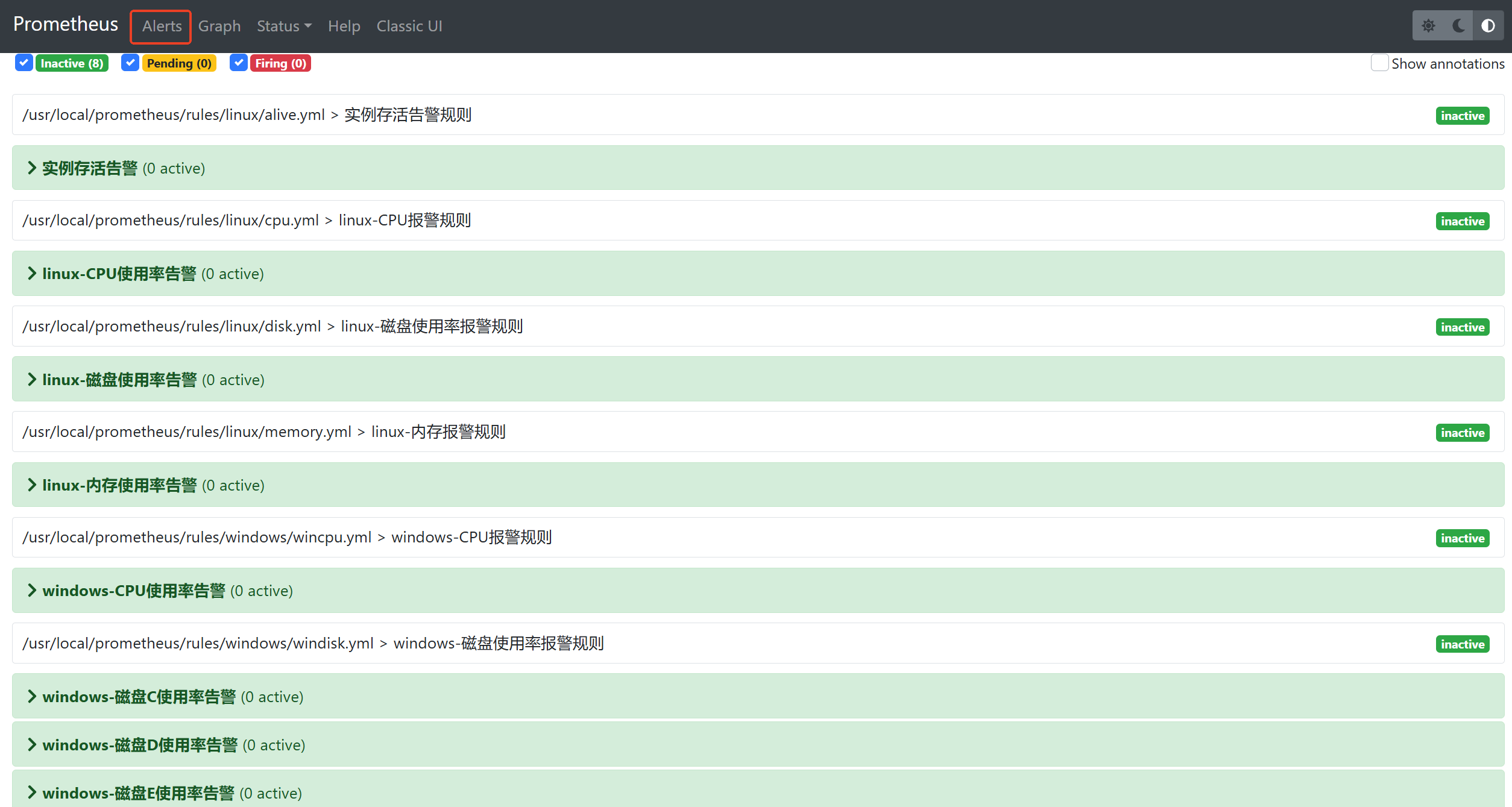
所有的规则都要在上述目录中,并以.yml结尾例如alive.yml
实例存活告警规则
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "主机宕机 !!!"
description: "该实例主机已经宕机超过一分钟了。"
Linux-cpu告警规则
groups:
- name: linux-CPU报警规则
rules:
- alert: linux-CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率过高"
description: "CPU使用率超过80%(当前值:{{ $value }}%)"
Linux-磁盘使用率告警规则
groups:
- name: linux-磁盘使用率报警规则
rules:
- alert: linux-磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "分区使用大于85%(当前值:{{ $value }}%)"
Linux-内存告警规则
groups:
- name: linux-内存报警规则
rules:
- alert: linux-内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "服务器可用内存不足。"
description: "内存使用率已超过80%(当前值:{{ $value }}%)"
Windows-cpu告警规则
groups:
- name: windows-CPU报警规则
rules:
- alert: windows-CPU使用率告警
expr: 100 - (avg by(instance) (irate(windows_cpu_time_total{mode="idle"}[1m])) * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率过高"
description: "CPU使用率超过80% (当前值:{{ $value }}%)"
Windows-磁盘使用率告警规则
groups:
- name: windows-磁盘使用率报警规则
rules:
- alert: windows-磁盘C使用率告警
expr: (windows_logical_disk_free_bytes{instance=~".*",volume="C:"} / windows_logical_disk_size_bytes{instance=~".*",volume="C:"}) * 100 < 15
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘C使用率过高"
description: "磁盘C剩余空间小于15% (当前磁盘C剩余空间:{{ $value }}%)"
- alert: windows-磁盘D使用率告警
expr: (windows_logical_disk_free_bytes{instance=~".*",volume="D:"} / windows_logical_disk_size_bytes{instance=~".*",volume="D:"}) * 100 < 15
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘D使用率过高"
description: "磁盘D剩余空间小于15% (当前磁盘D剩余空间:{{ $value }}%)"
- alert: windows-磁盘E使用率告警
expr: (windows_logical_disk_free_bytes{instance=~".*",volume="E:"} / windows_logical_disk_size_bytes{instance=~".*",volume="E:"}) * 100 < 15
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘E使用率过高"
description: "磁盘E剩余空间小于15% (当前磁盘E剩余空间:{{ $value }}%)"
规则写完并保存后
vi /usr/local/prometheus/prometheus.yml
修改规则存放路径并保存重启服务

systemctl restart prometheus.service
访问Prometheus服务端IP地址:9090查看告警规则